Joule: Decentralized Data Processing
Joule is a framework for decentralized data processing. Joule distributes computation into independent executable Module Configuration that are connected by Pipe Configuration which carry timestamped data flows called DataStream Configuration.
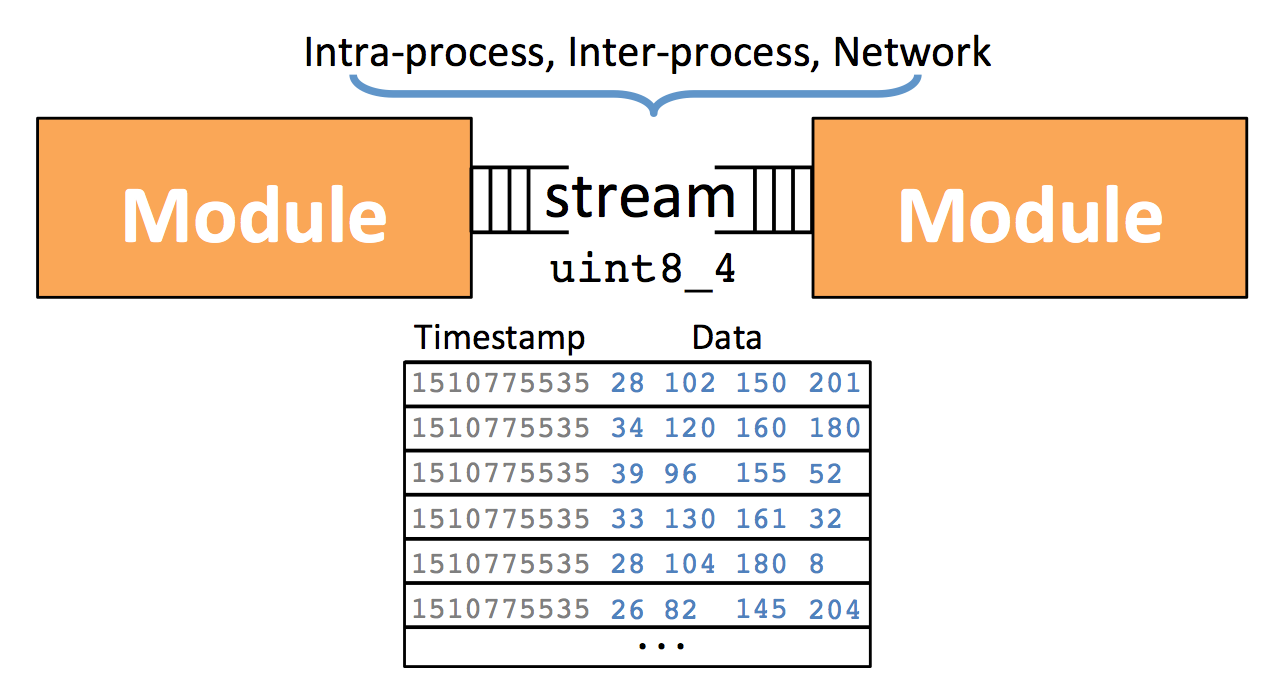
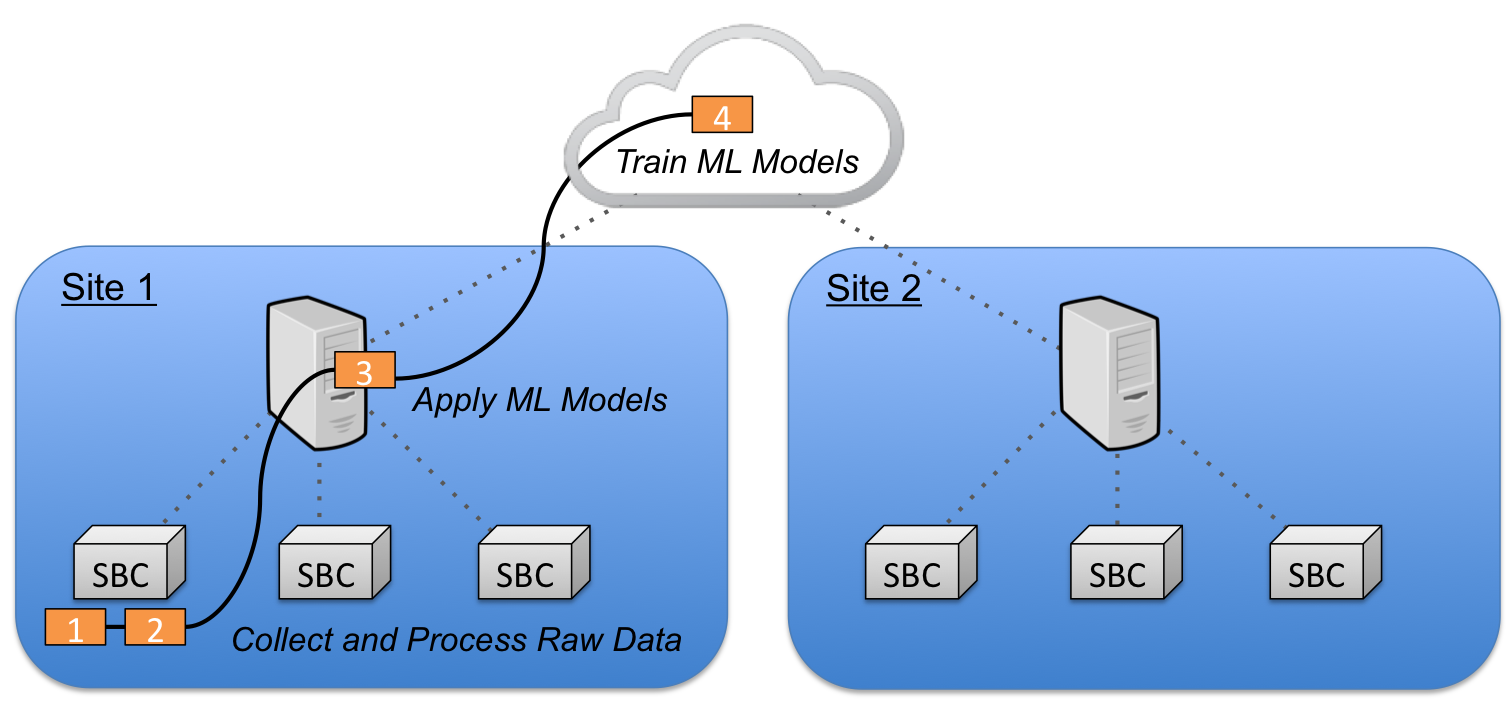
A typical deployment is shown below. Embedded sensors collect high bandwidth data (module 1) and perform feature extraction locally (module 2). This lower bandwidth feature data is transmitted to local nodes that convert this into actionable information by applying machine learning (ML) models (module 3). Aggregation nodes at the data center collect streams from a variety of local nodes and perform more computationally intensive tasks like training new ML models (module 4).
See the Quick Start for a hands-on introduction with an example data pipeline. Then read Configuration for more detailed information on how to configure Joule for your own pipelines.
Contributing & Running Tests
Contribution is always welcome. Please include tests with your pull request. Unittests can be run using unittest, see joule/htmlcov for code coverage.
$> cd joule
$> python3 -m unittest